所以在舞蹈评价方法中,我们要从姿态、节奏和力效三个方面进行分析,并在最后输出舞蹈学习者可以理解的指导语句。}gsr}0137-1.jpg}/gsr}其中,fk、fk分别表示关节运动状态的最大、最小值,这两个数值将参考人体生物力学以及舞蹈解剖学中对人体关节的定义和关节活动范围来设定。表3-2中的各关节特征值的极值范围,在实际测算过程中以舞蹈交互系统的空间坐标为准进行设定。......
2023-10-29
为了构建一个合理的S-SOFM对舞蹈姿态进行描述,我们需要以大量标准的舞蹈动作作为随机样本对该模型进行训练。因此,我们首先选取了一系列由舞蹈教师完成的适用于教学的标准舞蹈动作单元,制作出一个舞蹈动作样本库。所有的舞蹈动作都是通过Kinect动作传感器捕捉的。我们用公式(6)表示输入的样本空间,即舞蹈动作的库。
}gsr}0092-1.jpg}/gsr}
其中gc,n是c类动作的第n个动作片段,该片段包含m个动作姿态,如公式(7)所示,pm∈RD,是gc,n动作片段在第m个姿态的特征向量。
}gsr}0093-1.jpg}/gsr}
S-SOFM输出模型的节点数量以一个正二十面体为基础,通过多次训练细分的方式达到理想的水平状态L。在模型的第一级细分过程中会产生12个节点,而在第二级(l=2)和第三级(l=3)细分过程中分别会产生42个和162个节点。球面上的每个节点yk都会被随机分配一个初始权重向量值,这个值在训练中被不断更新,表示为wk(t)∈RD。在对舞蹈动作的学习与训练过程中,这些节点的权重向量便代表输入空间Xt里的一个关键姿态,节点的总数代表通过训练模型得到的关键姿态总量。在这个模型中,节点与它们的直接邻居间都是等距的,而这些距离就形成了六边形的邻域。
特征映射主要在模式识别研究领域中解决非线性分类问题,如图2-8所示。针对输入特征空间X(输入空间),需要通过一系列非线性变换的方法Φ得到新的特征空间Y,从而使原有的非线性分类变成可以直接使用的线性分类。
Φ:X→Y
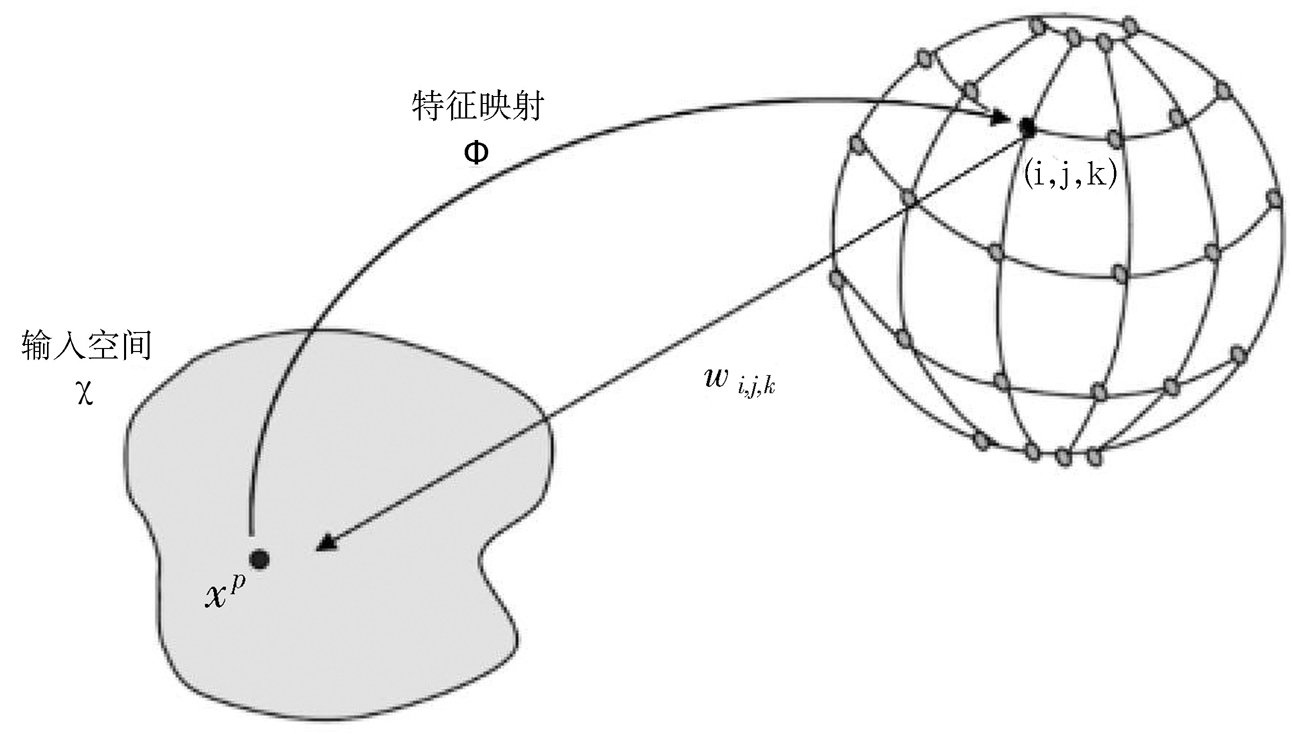
图2-8 特征映射示意图
在本书中,舞蹈动作是我们的研究对象,我们之所以选择特征映射的方法,主要是希望能够对舞蹈表演者的动作姿态进行更好的描述,使舞蹈姿态可以在输出的模型上实现最大限度的分离。因此,针对舞蹈动作的识别,我们选择以本章中所描述的动作特征模块中的身体构造和姿态的描述模块作为舞蹈动作的识别特征集合。S-SOFM映射中的节点将通过学习机制进行竞争,每个节点都代表来自Xt的一个输入特征向量。
在完成S-SOFM学习训练之后,每个节点都会表示一个典型的舞蹈姿态。对一个动作片段的描述就是将一个舞蹈动作离散成一组姿态序列,并将这个姿态序列投射到S-SOFM的输出空间中。对于每一个输入姿态来说,投射过程就是在找到输出球体上的最佳匹配节点(也被称为获胜节点)以后,使用这个节点的索引标号来标识输入的姿态。因此,如公式(8)所示,一个完整的舞蹈动作片段(一个由姿态构成的时间为T的序列)在完成向输出空间的投射之后,在输出空间上形成一段“轨迹”O(t)的同时,也会得到一组包含时序信息的索引标识号。
}gsr}0095-1.jpg}/gsr}
每一类舞蹈动作都可以用这样一组“独特”的索引号序列Oc,n来标识,我们把这组序列号信息称为定义一个舞蹈动作片段的基本信息模板。为了更好地对动作片段进行描述,在此基础上,我们用如下四种方法对动作片段的基本信息模板进行高层次的描述,并把它们作为用于识别的舞蹈动作模板:
(1)舞蹈姿态频率统计;
(2)舞蹈姿态的稀疏编码;
(3)舞蹈姿态变换矩阵;
(4)舞蹈姿态变换矩阵的稀疏编码。
从逻辑上看,舞蹈的基本信息模板类似于在自然语言处理和信息检索(IR)领域中比较流行的bag-of-words(BOW)词袋模型。在输出的球体模型中,每一个节点所代表的姿态都可以被看作一个特殊的词条,而一个动作片段可以被看成根据特定的文法规则组合在一起的一组词条。在应用词袋模型的文件分类研究中,统计关键词出现的频率可以被看作训练分类器的一个重要特征。本书借鉴了词袋模型中的词频特征分类方法,把舞蹈动作片段里面的姿态序列按照出现频率进行统计,从而形成了一个动作片段或一组类似动作的“直方图”。每个舞蹈动作片段的直方图都是由该动作所包含的姿态的频率统计值构成的,两个舞蹈动作的相似性可以通过直方图间的相似距离来度量。依照直方图的统计规则,一个动作序列(包含n个姿态)的直方图可以用如下公式表示:
}gsr}0096-1.jpg}/gsr}
在上面的公式中,动作基本模板中的第u个输出节点fu是舞蹈动作中第u个输出节点的出现频率,n表示该舞蹈所包含的姿态数量。那么一系列动作就可以通过平均直方图Hc,n来表示,如公式(10),其中c=1,2…L,c代表了一组动作片段的类别。
}gsr}0096-2.jpg}/gsr}
若同样的舞蹈动作由不同的表演者进行表演,则速度上可能会存在一定的差异;如果两个动作的顺序和造型是相似的,那么人们从主观视觉上进行判定,会认为两个动作属于一类动作,或者说两个动作是相似的。[16]Kawashima等人在姿态识别研究中尝试使用层次化的稀疏编码作为动作模板,通过把动作的速度看成时间常量来对动作进行描述,以此实现对动作类别的提前判定。在舞蹈姿态的稀疏编码表示方法中,对于每一个姿态的描述,不再仅仅是把获胜的神经元节点列出来并作为描述的对象,而是以所有的神经元节点为信息描述对象,通过设定每个神经元节点的状态,利用稀疏编码的描述方法,检查每个输出节点在该动作里是否发生过,但无法表示这些姿态持续的时间,因此这样的描述方式适用于对速度不同、内容相同的动作进行预判。(www.chuimin.cn)
某一个舞蹈动作gc,n在输出模型上形成轨迹Oc,n,如公式(11)所示,Su表示输出节点的状态,如果该节点所代表的姿态属于舞蹈动作轨迹,则设定状态为1,否则为0。通过这种方式,对于每一个动作,我们都会得到一个输出节点的向量集合S={s1,s2,s3,…,sN}。
}gsr}0098-1.jpg}/gsr}
同理,公式(12)可以描述一系列动作的稀疏编码。
}gsr}0098-2.jpg}/gsr}
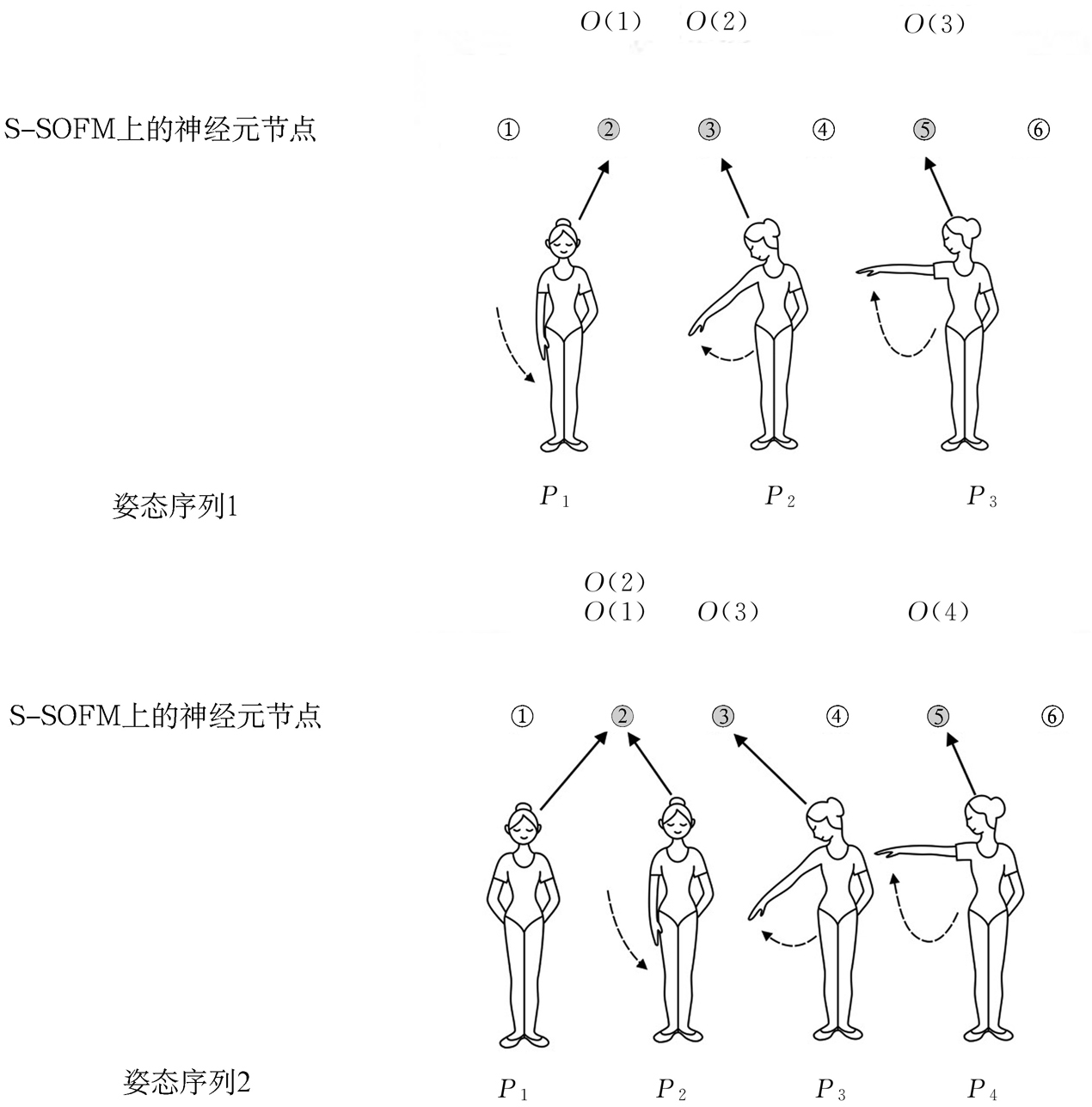
图2-9 稀疏编码原理示意图
前两种动作描述方法都是以舞蹈动作中的单个姿态作为描述对象的,没有考虑舞蹈动作的空间和时间的关系。考虑到舞蹈动作姿态序列之间存在着很强的时序关系,本书通过对舞蹈姿态之间的变换关系进行统计分析,以此来描述一段舞蹈动作。一段舞蹈动作在完成向输出空间的映射之后,在输出的球体上可以得到一组对应映射节点的有序索引标识号,Oc,n(t)={ot},t∈T。若设定滑动窗口为2,我们可以对片段中相邻姿态之间的转换频率进行统计。假设S-SOFM模型具有N个输出节点,那么可以形成一个N×N的转移矩阵A,其中Ai,j表示输出空间中第i个节点所表示的姿态到第j个节点所表示的姿态的转换频率,因此,转移矩阵A也可以被看成一个二维的动作转换关系的直方图。
和舞蹈姿态的稀疏编码方法类似,在转换矩阵A中,可通过公式(13)对每个姿态转换状态进行表示,也就是说,只表示该动作存在这个姿态转换,不代表这个姿态发生转换的频率。在一个舞蹈动作中,如果一直保持一个姿态,那么这个姿态和自身进行转换的次数会很多,在稀疏编码的表示方法中就会被过滤掉。
}gsr}0100-1.jpg}/gsr}
在前文中,我们通过对大量的舞蹈动作进行分类学习,构建了S-SOFM神经网络模型,以便对舞蹈动作进行检索和分类。对于新的输入动作片段,首先需要将该动作片段自动离散成姿态序列并投射到我们所构建的输出空间,然后提取一组对应输出空间节点的索引标识号,并在此基础上生成一个动作模板,通过和已知的动作模板进行匹配计算,判断新输入动作所属的类别。在舞蹈交互系统中,这个识别过程可以离线完成,也可以在线完成。使用舞蹈交互系统时,学习者在模仿老师的舞蹈动作的过程中,需要不断地进行练习,系统会及时、有效地识别学习者的“不标准”的舞蹈动作,这对使学生保持学习兴趣和加强学习反馈效果都发挥着很重要的作用。本书重点讨论舞蹈动作的在线识别方法。受Kawashima等人[17]工作的启发,我们在舞蹈交互系统中设计了一个在线舞蹈动作识别模块。
如图2-10所示,对学习者的舞蹈练习动作采用贝叶斯估计法,主要是实时地把输入的姿态特征向量投射到S-SOFM模型的输出空间,得到一个时间持续增加的标识序列Su;把它作为已知样本,根据我们在第一章所构建的舞蹈动作模板描述方法,将它转化成动作模板,然后基于不同类别的动作模板进行动态估算,
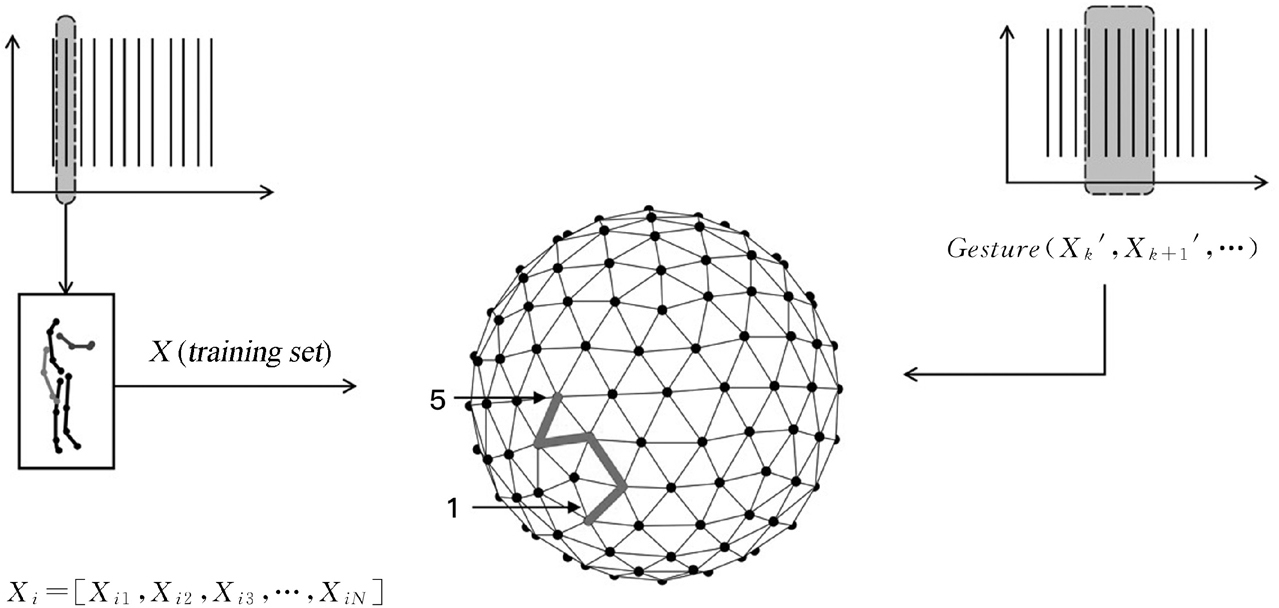
图2-10 识别流程示意图
从而得到一个不断更新的后验概率P(c|ht),c=1…C,依据这个概率来预估,再累加将要出现的新舞蹈姿态属于动作c的概率。根据四种舞蹈动作模板的特点,我们可以把动作发生的概率定义为一个逐渐增加的舞蹈动作序列Su(包括从时间t0到t的所有姿态)的姿态频率统计的直方图(或者姿态变换矩阵)和每类标准舞蹈动作的直方图之间的交叉核,或者是舞蹈动作序列Su的稀疏编码(姿态转换矩阵的稀疏编码)和每类标准舞蹈动作的稀疏编码的比值。在这个前提下,根据贝叶斯后验概率估计算法,可得到公式(14)-(17),其中,ht为t时刻根据动作模板描述方法来统计的姿态集合,hc为c类舞蹈对应的动作模板,Pt(c|ht)就是我们需要得到的后验概率,Pt(c)表示动作为c类的可能性。
}gsr}0102-1.jpg}/gsr}
}gsr}0102-2.jpg}/gsr}
}gsr}0102-3.jpg}/gsr}
}gsr}0102-4.jpg}/gsr}

图2-11 计算流程
当实时动作在样本库里寻找类似的动作片段的时候,随着后验概率超过阈值T,具有最大后验值的那个动作类别c就是我们检测的识别结果,然后系统重置所有先验概率值,并重新开始计算输入动作序列的后验概率值(见图2-11)。为了从已经检测过的姿态序列中释放姿势,需将t0设置为当前时间,因此新输入的序列会再次重复该过程,这个过程一直到输入序列结束。
有关人工智能舞蹈交互系统原理与设计的文章

所以在舞蹈评价方法中,我们要从姿态、节奏和力效三个方面进行分析,并在最后输出舞蹈学习者可以理解的指导语句。}gsr}0137-1.jpg}/gsr}其中,fk、fk分别表示关节运动状态的最大、最小值,这两个数值将参考人体生物力学以及舞蹈解剖学中对人体关节的定义和关节活动范围来设定。表3-2中的各关节特征值的极值范围,在实际测算过程中以舞蹈交互系统的空间坐标为准进行设定。......
2023-10-29
在动作识别的过程中,舞蹈动作被看作一系列姿态的时间序列。在舞蹈交互系统中,无论是动作的识别还是动作的分析与评估,都需要采用一种有效的方式对动作进行清晰的定义和可量化的描述。在后续的舞蹈交互系统中,针对动作识别和动作评估这两个研究领域,笔者将使用不同的特征子集来进行有针对性的研究。......
2023-10-29

然而在舞蹈表演中,舞者经常以各种方式弯曲、倾斜或旋拧他们的躯干,通过这样的动作来表现富有魅力的形体之声。和Yu轴之间的夹角θLE表示左大臂的“倾斜”状态。......
2023-10-29

基于上一章提出的舞蹈姿态的时空特征提取方法,针对形成的新的舞蹈动作特征集合,本章将利用S-SOFM构建一个有效的输出模型,对舞蹈动作进行聚类和分析,从而实现舞蹈动作的识别。图2-6 离散的姿态序列本书采用S-SOFM来构建输出模型。此外,由于保留了SOFM的特点,因此数据样本在重复训练分类之后生成的S-SOFM的各神经元节点之间的拓扑映射关系与原始输入样本一样。......
2023-10-29
在他们的实验中,专业舞者动作的特征向量和初学者动作的特征向量显示出很大的差异,这证明该方法对日本民族舞蹈动作的分类识别是有效的。图3-1 动作评价系统架构本章从舞蹈教学的需求出发,将拉班动作分析理论与舞蹈教学中常用指导用语的特点结合,提出一个基于拉班运动分析理论的动作评估模型。......
2023-10-29

学生与VR系统的交互有3个步骤。图3-17是计算得到的学生动作的关键帧和老师动作的关键帧的对比图,总体来说,学生存在抢拍的情况,前面部分的节奏相对于老师的来说稍微快点儿,后半部分节奏正常。图3-18是以两个动作的关键帧为时间点,计算得出的学生左臂和右臂的偏离、扩展评估曲线。第二组实验主要是为了分析学生在系统中的学习效果,我们邀请学生A和B学习数据库中的动作并对其进行评价分析。......
2023-10-29

轨迹上的实心标记分别代表动作的起点和动作的终点。L1距离的定义如下:L2距离的定义如下:L3距离的定义如下:第二个实验方案的执行过程完全一样,只不过训练生成动作单元模板的动作集在动作库中的比例变为40%,而剩下的60%用来测试识别能力。基于不同的动作模板的实验结果见表2-4至表2-7。表2-10 第三组实验的识别率统计在第四组实验中,我们加入了动作集合2,这样一共有30种动作。......
2023-10-29

到目前为止,针对运动特征描述和提取方法的研究大致可以分为三类。Muller等人[5]针对这个问题在后续的研究中又提出了“运动模板”的概念。因此,Muller在文献中也指出布尔几何特征描述方法不能对动作的细节进行细致的描述,只适用于普通的运动描述。因此,每一个人体姿态就可以表示为由八个夹角构成的特征集合。......
2023-10-29
相关推荐